Prompt 编写
LLM(Large Language Model,大型语言模型)的Prompt是对模型的一种输入,通常是一段文字,用以引导模型产生特定的回应或执行特定的任务。这段文字可以是一个问题、一段描述、指令或者任何形式的语句,目的是为了告诉模型用户想要得到什么样的信息或结果。例如,你的提问 “Prompt是什么?” 就是一个Prompt,它引导 LLM 提供关于 Prompt 的解释。
基础的提示工程方法
- zero-shot learning: 表示不使用任何样例对模型做微调;
- few-shot learning: 表示使用少量样例对模型做微调;
- in-context learning(ICL): 首次出现在GPT3的论文中,表示有少量样例,但是这些样例不用于微调、不更新模型的权重,仅在推理时使用。
这个 few-shot learning 与 in-context learning 的区别就是一个更新权重,一个不更新权重。但是在很多资料中,他的操作并没有更新权重,使用的术语却是 few-shot learning。
目前的策略中有以下两种策略即可:
- 使用少量数据更新权重的策略;
- 不更新权重,仅将少量数据在推理时使用的策略。
CoT prompting
出自论文: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
CoT 的全称即 chain-of-thought(思维链)。该方法用一句话表述就是:将思考和推理的过程也教给模型,帮助模型提高其推理能力。下面使用例子具体描述该方法的操作细节。
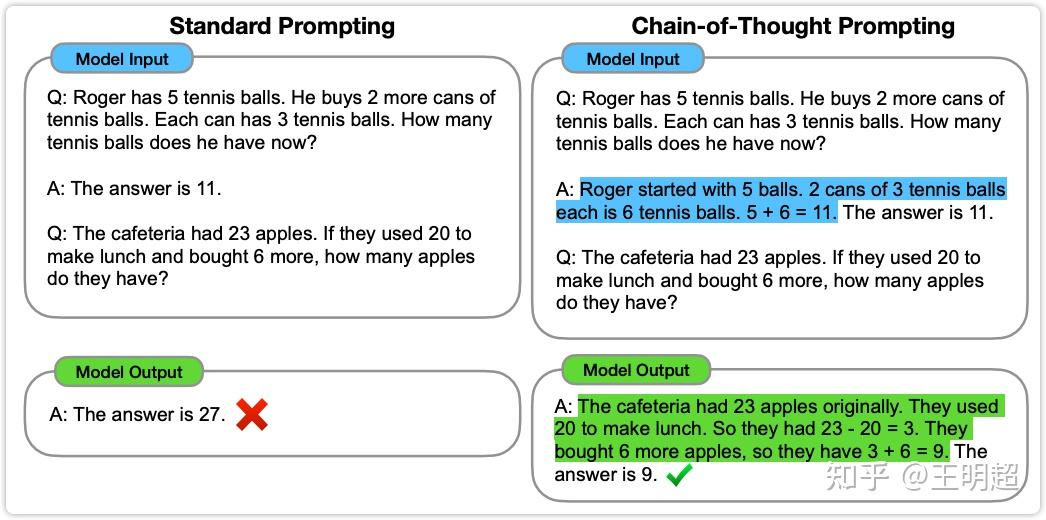
上图1中的左侧部分是标准提示的方法。在 "Model Input" 中第一组 QA 是给模型的样例,在该样例中直接给出了答案是 11,并没有给出这个答案是如何得到的。对应的中文如下:
Q: Roger有5个网球。他又买了2罐网球。每罐有3个网球。他现在有多少个网球?
A: 答案是11。
于是模型在回答第二个问题时,参考了第一组样例中的方式,直接给出了问题的答案,也就是27,但是这个答案是错误。
上图 1 的右侧部分是 CoT prompting 方法。在 "Model Input" 中第一组 QA 还是给模型的样例,但是在这组样例的回答中并不是直接给出答案,而是先给出了推理过程(图中蓝色部分),后给出了答案。这种做法的直观理解就是告诉模型如何一步一步的推理,希望模型在做其他问题时也是一步一步推理然后得出最终结果。
于是模型在回答第二个问题的 "Model Output" 中,也是模仿例子先一步一步生成推理过程(图中绿色部分),然后给出答案。相同的问题,这个模型给出了正确的答案。对应的中文如下:
Q: Roger 有 5 个网球。他又买了 2 罐网球。每罐有 3 个网球。他现在有多少个网球?
A: Roger 最初有 5 个球。2 罐网球,每罐 3 个,共 6 个网球。5+6=11。答案是 11。
该方法在数学推理测试集GSM8K上,将指标提升到了60.1%左右。
zero-shot CoT
出自论文: Large Language Models are Zero-Shot Reasoners
上一部分的 CoT 方法需要至少给出一个例子,也就是 few-shot 方法,然后就又提出了一种 zero-shot 的思维链方法,下面结合具体例子进行说明。
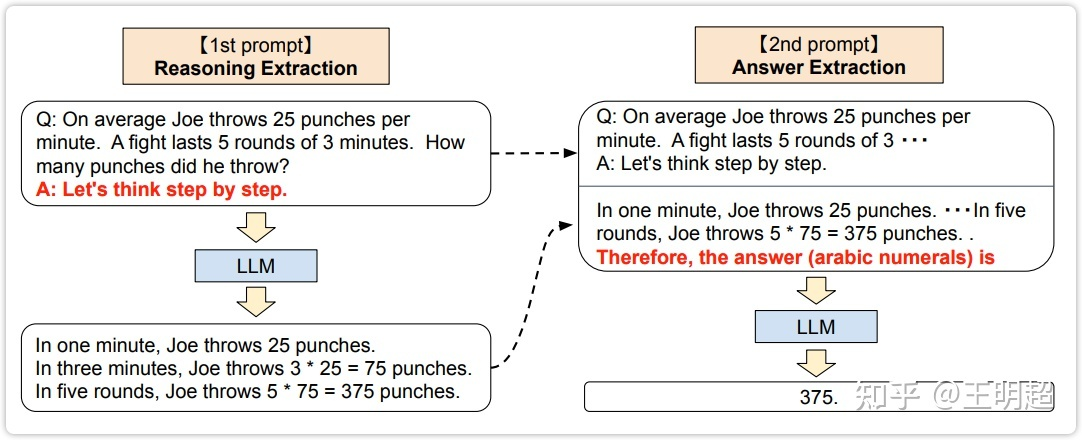
原来是给定 question,让模型直接输出 answer。而 zero-shot 思维链方法则将该过程拆分为两步。
第一步:
在原始的问题后面添加上固定的一句话: "Let's think step by step."(让我们一步一步地思考)。然后输入给模型,让模型进行输出。如上图2 的左侧部分所示。
上图2 的左下侧为模型的输出,可以看出在增加了 "Let's think step by step." 这么一句话之后模型的输出确实是在逐步的思考让它推理的内容。上图2 左侧部分对应的中文如下:
---模型的输入:---
Q: Joe平均每分钟出拳25次。一场战斗持续5轮,每轮3分钟。他打了多少拳?
A: 让我们一步一步地思考。
---模型的输出:---
一分钟内,乔出拳25次。
三分钟内,乔出拳3*25=75次。
在五个回合中,乔出拳5*75=375次。
第二步:
在第一步模型的输入的基础上,将第一步的模型的输出也拼接上去,然后再加上固定的一句话: "Therefore, the answer (arabic numerals) is"(因此,答案(阿拉伯数字)是)。将拼接后的整个内容输入模型,此次模型的预测结果就是最终结果。如上图2 的右侧所示,对应的中文如下:
---模型的输入:---
Q: Joe平均每分钟出拳25次。一场战斗持续5轮,每轮3分钟。他打了多少拳?
A: 让我们一步一步地思考。
一分钟内,乔出拳25次。
三分钟内,乔出拳3*25=75次。
在五个回合中,乔出拳5*75=375次。
因此,答案(阿拉伯数字)是
---模型的输出:---
375
该方法在数学推理测试集GSM8K上,将指标由10.4%提升到了40.4%。
Self-Consistency
出自论文: Self-Consistency Improves Chain of Thought Reasoning in Language Models
该方法就更简单了,该方法主要利用的是模型每次生成的结果都不是完全相同的这个性质。
本文第二部分介绍的 CoT prompting 方法是每条数据仅使用模型推理一次,直接使用模型的推理结果作为最终结果。该方法是每条数据使用模型推理多次,然后在多条生成结果中统计每个结果的频次,选取频次最高的那个结果最终最终结果。
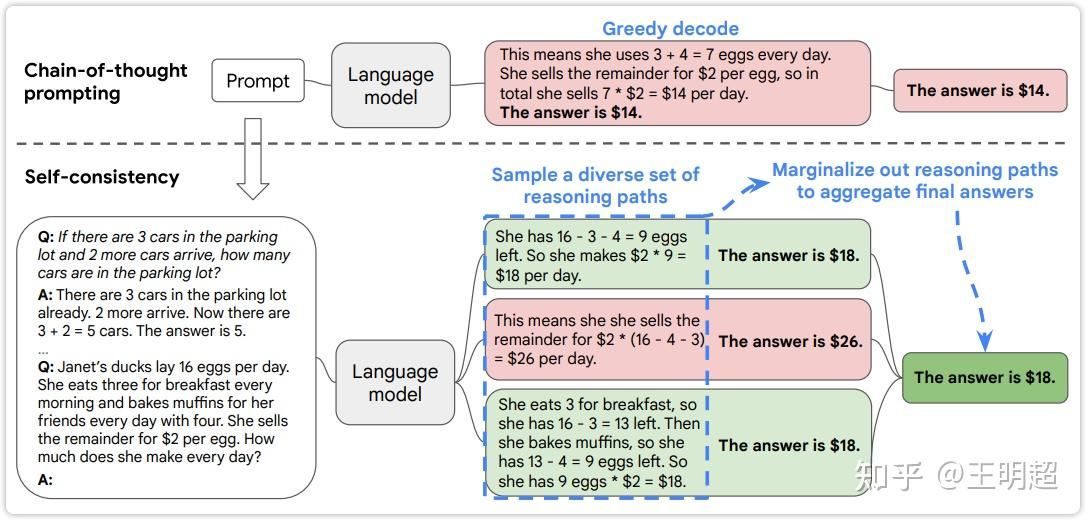
结合下图3 中的例子进行说明,下图3 中灰色虚线上面展示的是 CoT prompting 的方法;灰色虚线下面展示的是 Self-Consistency 方法。CoT prompting 是预测出一个结果就直接使用这个结果;而 self-consistency 就是先用 CoT prompting 方法预测出多个结果,然后选择预测出频次最多的那个结果。像下图3 中预测了三次,两次的结果是 18,一次的结果是 26,那么最终结果选取 18.
该方法在数学推理测试集GSM8K上,将指标提升到了74.4%左右。
Least-to-Most(分而治之)
出自论文: Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
原论文中该方法名字为 Least-to-Most Prompting,然后其思想非常像是分治思想,就是把大问题拆分成小问题,先解决小问题,后解决大问题。以下图4中的例子进行说明。
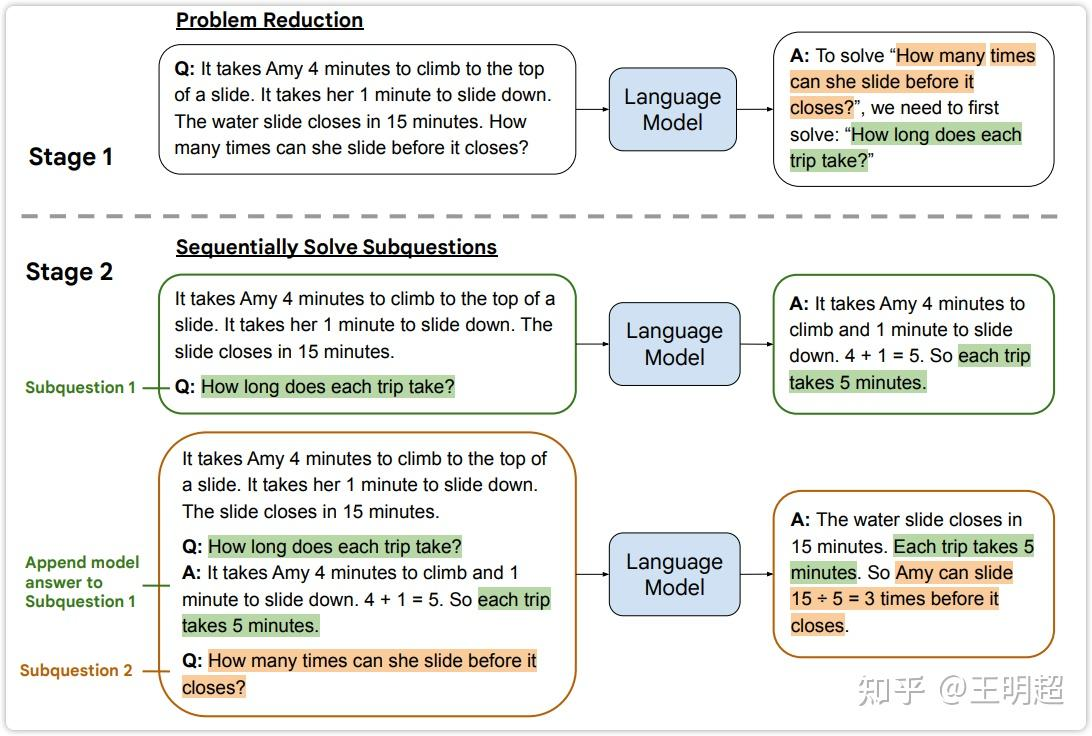
如上图4中所示,背景描述为:"Amy 爬到滑梯顶端需要4分钟。她需要1分钟才能滑下来。水滑梯将在15分钟后关闭",原始的问题为:"How many times can she slide before it closes?"(在关闭之前她可以滑动多少次)
Stage 1:
在阶段一时并不指望模型直接回答原始的问题,而是在原问题的基础上拼接上如下模板的一段话,输入给模型,期待模型输出原问题的子问题。
To solve "[这里放原问题]", we need to first solve:
在上图4 的第一阶段可以看出,模型的输出为 "How long does each trip take?"(每次滑动需要多长时间)。这确实是原问题的一个子问题,解决了这个子问题之后对解决原问题是有帮助的。上图4 的第一阶段对应的中文为:
---模型的输入:---
Q: Amy爬到滑梯顶端需要4分钟。她需要1分钟才能滑下来。水滑梯将在15分钟后关闭。在关闭之前她可以滑动多少次?
要解决"在关闭之前她可以滑动多少次?",我们需要先解决:
---模型的输出:---
每次滑动需要多长时间?
Stage 2:
在阶段二中先让模型解决它自己在第一阶段生成的子问题;然后把子问题的答案拼接到输入中,再解决原问题。整个操作和之前都是类似的,如上图4 灰色虚线下侧的 Stage 2 所示,需要注意的是这里的阶段二并不是只需要模型推理一次,在阶段二里需要模型推理两次。其对应的中文为:
---模型的输入:---
Amy爬到滑梯顶端需要4分钟。她需要1分钟才能滑下来。水滑梯将在15分钟后关闭。
Q: 每次滑动需要多长时间?
---模型的输出:---
Amy爬上去需要4分钟,滑下需要1分钟。4+1=5。所以每次滑动需要5分钟。
---模型的输入:---
Amy爬到滑梯顶端需要4分钟。她需要1分钟才能滑下来。水滑梯将在15分钟后关闭。
Q: 每次滑动需要多长时间?
A: Amy爬上去需要4分钟,滑下需要1分钟。4+1=5。所以每次滑动需要5分钟。
Q: 在关闭之前她可以滑动多少次?
---模型的输出:---
水滑梯将在15分钟后关闭。每次滑动需要5分钟。所以Amy可以在它关闭之前滑动15÷5=3次。